University CTF 2025: Tinsel Trouble experience (and writeups)

The University CTF 2025: Tinsel Trouble, mainly for University students/teams event lasted from December 19th-21st 2025.
Represented Western Washington University solo, finished 114th out of 1014 University teams (or against 5284 total players). Top ~2% individual performer; top ~11% institutional result.

This write-up will be about selection of challenges (mainly Crypto, Reversing, and Coding categories) from the competition, providing a breakdown of the methodologies and exploitation vectors used to solve them. I will try to be more brief here compared to my last CTF solutions writeup.
List of solutions to the challenges (by order):
- [Reversing] — “CloudyCore”
- [Reversing] — “Clock Work Memory”
- [Reversing] — “Starshard Reassembly”
- [Crypto] — “Disguised”
- [Coding] — “Cellcode”
- [Coding] — “Bauble Sort”
- [Coding] — “Flickering Snowglobe”
You can also [CTRL + F] and input the title challenge to jump to specific one.
[Reversing] — “CloudyCore”
“Twillie, the memory-minder, was rewinding one of her snowglobes when she overheard a villainous whisper. The scoundrel was boasting about hiding the Starshard’s true memory inside this tiny memory core (.tflite). He was so overconfident, laughing that no one would ever think to reverse-engineer a ‘boring’ ML file. He said he ‘left a little challenge for anyone who did,’ scrambling the final piece with a simple XOR just for fun. Find the key, reverse the laughably simple XOR, and restore the memory.”
Files provided
snownet_stronger.tflite
Goal
Extract the hidden “true memory” from a TensorFlow Lite model. The challenge text states:
- the final piece is scrambled with a simple XOR
- the key is recoverable from the model itself
1) Recon: what is a .tflite and where can data hide?
A .tflite file is a FlatBuffer container. In practice, it often contains multiple constant buffers:
- weights (float / int tensors)
- small lookup tables
- metadata blobs
That makes it an easy place to hide arbitrary bytes without looking suspicious.
A hexdump confirms it’s a TFLite FlatBuffer via the magic string:
- File header contains
TFL3
2) Finding the XOR key inside “weights”
The key was embedded in a 16-byte block where every 4-byte group begins with an ASCII character. Searching for bytes that match:
data[i] == 'k'data[i+4] == '3'data[i+8] == 'y'data[i+12]== '!'
produces one hit.
At offset 0x214 (decimal 532), the 16 bytes are:
6b 00 40 00 33 00 40 00 79 00 40 00 21 00 40 00Split into 4-byte chunks:
6b 00 40 00→ first byte0x6b→'k'33 00 40 00→ first byte0x33→'3'79 00 40 00→ first byte0x79→'y'21 00 40 00→ first byte0x21→'!'
So the repeating XOR key is:
k3y!
3) Locating the encrypted payload
With the key known, the next step is to find what was XORed.
A useful heuristic:
- after XOR-deobfuscation, many CTF payloads reveal a recognizable file signature
- the restored bytes might begin with a common magic/header (e.g., zlib, gzip, PNG, etc.)
The solution used a scan for 36-byte windows in the file that, when XORed with k3y!, produce something that:
- starts with
0x78 0x9c(a very common zlib header) - successfully decompresses via
zlib.decompress(...) - yields printable text containing
HTB{...}
This found exactly one candidate.
At offset 0x238 (decimal 568), the 36-byte encrypted blob is:
13 af 8a 29 1a 99 0f ef 5a 1b 34 88 e7 44 4f 09
59 bd 76 13 45 00 57 0b 5d 7d d0 24 6b 5e 5b 29
e3 00 00 004) Reverse the XOR
XOR deobfuscation with a repeating key:
plain[i] = enc[i] XOR key[i mod len(key)]Using key = b'k3y!' yields bytes starting with 78 9c …, a zlib stream.
5) Decompress zlib to restore the “memory”
Decompressing the XOR recovered zlib stream reveals flag:
HTB{Cl0udy_C0r3_R3v3rs3d}

Solver Script
#!/usr/bin/env python3
import zlib
from pathlib import Path
d = Path("snownet_stronger.tflite").read_bytes()
kpos = next(i for i in range(len(d)-16) if d[i:i+13:4] == b"k3y!")
k = d[kpos:kpos+13:4]
print(f"key offset: 0x{kpos:x}\nkey: {k.decode()}")
for i in range(len(d)-36):
dec = bytes(b ^ k[j & 3] for j, b in enumerate(d[i:i+36]))
if dec[:2] == b"\x78\x9c":
try: out = zlib.decompress(dec)
except zlib.error: continue
if b"HTB{" in out and all(32 <= c < 127 for c in out):
print(f"blob offset: 0x{i:x}\nflag: {out.decode()}")
break
else:
raise SystemExit("not found")[Reversing] — “Clock Work Memory”
Overview
The file is a small WebAssembly module that exposes a function named check_flag. The objective is to determine what input causes check_flag to return success. The solve path is to inspect the module’s exports and data, understand how check_flag derives the expected string, and then reconstruct that string offline.
Files provided
pocketwatch.wasm
1) Inspecting the module
The first step is to list exports and view the text form.
wasm-objdump -x pocketwatch.wasm
&
wasm2wat pocketwatch.wasm -o pocketwatch.watpocketwatch.wasm: file format wasm 0x1
Section Details:
Type[4]:
- type[0] () -> nil
- type[1] (i32) -> i32
- type[2] (i32) -> nil
- type[3] () -> i32
Function[4]:
- func[0] sig=0 <_initialize>
- func[1] sig=1 <check_flag>
- func[2] sig=2 <_emscripten_stack_restore>
- func[3] sig=3 <emscripten_stack_get_current>
Table[1]:
- table[0] type=funcref initial=2 max=2
Memory[1]:
- memory[0] pages: initial=258 max=258
Global[1]:
- global[0] i32 mutable=1 - init i32=66592
Export[6]:
- memory[0] -> "memory"
- func[1] <check_flag> -> "check_flag"
- table[0] -> "__indirect_function_table"
- func[0] <_initialize> -> "_initialize"
- func[2] <_emscripten_stack_restore> -> "_emscripten_stack_restore"
- func[3] <emscripten_stack_get_current> -> "emscripten_stack_get_current"
Elem[1]:
- segment[0] flags=0 table=0 count=1 - init i32=1
- elem[1] = ref.func:0 <_initialize>
DataCount:
- data count: 1
Code[4]:
- func[0] size=3 <_initialize>
- func[1] size=159 <check_flag>
- func[2] size=6 <_emscripten_stack_restore>
- func[3] size=4 <emscripten_stack_get_current>
Data[1]:
- segment[0] memory=0 size=23 - init i32=1024
- 0000400: 1c1b 0130 237b 3026 0b3d 703d 0b7e 3014 ...0#{0&.=p=.~0.
- 0000410: 377f 7327 756e 3e 7.s'un>(module
(type (;0;) (func))
(type (;1;) (func (param i32) (result i32)))
(type (;2;) (func (param i32)))
(type (;3;) (func (result i32)))
(func (;0;) (type 0)
nop)
(func (;1;) (type 1) (param i32) (result i32)
(local i32 i32 i32 i32)
global.get 0
i32.const 32
i32.sub
local.tee 2
global.set 0
local.get 2
i32.const 1262702420
i32.store offset=27 align=1
loop ;; label = @1
local.get 1
local.get 2
i32.add
local.get 2
i32.const 27
i32.add
local.get 1
i32.const 3
i32.and
i32.add
i32.load8_u
local.get 1
i32.load8_u offset=1024
i32.xor
i32.store8
local.get 1
i32.const 1
i32.add
local.tee 1
i32.const 23
i32.ne
br_if 0 (;@1;)
end
local.get 2
i32.const 0
i32.store8 offset=23
block ;; label = @1
local.get 0
i32.load8_u
local.tee 3
i32.eqz
local.get 3
local.get 2
local.tee 1
i32.load8_u
local.tee 4
i32.ne
i32.or
br_if 0 (;@1;)
loop ;; label = @2
local.get 1
i32.load8_u offset=1
local.set 4
local.get 0
i32.load8_u offset=1
local.tee 3
i32.eqz
br_if 1 (;@1;)
local.get 1
i32.const 1
i32.add
local.set 1
local.get 0
i32.const 1
i32.add
local.set 0
local.get 3
local.get 4
i32.eq
br_if 0 (;@2;)
end
end
local.get 3
local.get 4
i32.sub
local.set 0
local.get 2
i32.const 32
i32.add
global.set 0
local.get 0
i32.eqz)
(func (;2;) (type 2) (param i32)
local.get 0
global.set 0)
(func (;3;) (type 3) (result i32)
global.get 0)
(table (;0;) 2 2 funcref)
(memory (;0;) 258 258)
(global (;0;) (mut i32) (i32.const 66592))
(export "memory" (memory 0))
(export "check_flag" (func 1))
(export "__indirect_function_table" (table 0))
(export "_initialize" (func 0))
(export "_emscripten_stack_restore" (func 2))
(export "emscripten_stack_get_current" (func 3))
(elem (;0;) (i32.const 1) func 0)
(data (;0;) (i32.const 1024) "\1c\1b\010#{0&\0b=p=\0b~0\147\7fs'un>"))The export list shows an exported memory and an exported function check_flag.
2) Reading check_flag
In the decompiled/text form, check_flag has 3 behaviors that matter.
It creates a small stack buffer intended to hold a decoded string. It then writes a 32-bit constant into its stack frame and later reads those bytes as a repeating key. After that, it reads a fixed length byte sequence from linear memory, XORs it with the repeating key, writes the decoded bytes into the buffer, appends a NUL terminator, and finally compares the caller-provided input string against the decoded buffer with a strcmp-style loop.
This means the expected flag is not stored directly as plaintext but is stored as an encoded blob plus a key.
3) Recovering the XOR key
The function stores the constant 0x4b434f54 into memory. WebAssembly linear memory is little-endian, so this 32-bit word becomes the byte sequence 54 4f 43 4b, which corresponds to ASCII T O C K. That yields a four-byte repeating XOR key, the string TOCK.
At this point the decoding rule is clear: take each encoded byte and XOR it with the corresponding byte of TOCK, repeating every four bytes.
4) Locating the encoded bytes
The next step is to find where the encoded bytes live. In the data section there is a data segment placed at memory offset 1024 (0x400) with a length of 23 bytes. That matches the decode loop’s bounds in check_flag. The function reads exactly those 23 bytes, decodes them, and terminates the output with \0.
Extracting those 23 bytes from the data segment gives
data = b"\x1c\x1b\x010#{0&\x0b=p=\x0b~0\x147\x7fs'un>"5) Decoding the flag
With the key and the encoded data, the plaintext is obtained by XORing each byte with the repeating key TOCK.
data = b"\x1c\x1b\x010#{0&\x0b=p=\x0b~0\x147\x7fs'un>"
key = b"TOCK"
flag = bytes([data[i] ^ key[i & 3] for i in range(len(data))])
print(flag.decode())
[Reversing] — “Starshard Reassembly”
Files provided
memory_minder
Goal
- Recover the required 28-byte input (“scrambled memory”)
- Recover the printed “truth” (flag)
1) Recon: identify the binary and language
Running basic identification:
file memory_minder
memory_minder: Mach-O 64-bit x86_64 executable, flags:<|DYLDLINK|PIE>
strings -a memory_minder | head
__PAGEZERO
__TEXT
__text
__TEXT
__symbol_stub1
__TEXT
__rodata
__TEXT
__DATA_CONST
__rodataObservations:
- The binary is Mach-O 64-bit x86_64.
- It contains typical Go runtime artifacts (large binary, many symbols/strings).
stringsincludesgo1.25.4, indicating it was built with a Go toolchain reporting that version.
For disassembly on Linux/macOS, llvm-objdump works on Mach-O:
llvm-objdump --syms memory_minder | headmemory_minder: file format mach-o 64-bit x86-64
SYMBOL TABLE:
00000000010d0a58 l O __TEXT,__rodata _$f64.3eb0000000000000
00000000010d0a60 l O __TEXT,__rodata _$f64.3f847ae147ae147b
00000000010d0a28 l O __TEXT,__rodata _$f64.3fd0000000000000
00000000010d0a68 l O __TEXT,__rodata _$f64.3fd3333333333333
00000000010d0a30 l O __TEXT,__rodata _$f64.3fe0000000000000
00000000010d0a70 l O __TEXT,__rodata _$f64.3fe80000000000002) Locate the validation logic
Instead of following the Go runtime entrypoints, list symbols and focus on main:
llvm-objdump --syms memory_minder | grep -E '_main\.main|_main\.R[0-9]+\.'00000000010a6380 l F __TEXT,__text _main.R0.Expected
00000000010a6360 l F __TEXT,__text _main.R0.Match
00000000010a63c0 l F __TEXT,__text _main.R1.Expected
00000000010a63a0 l F __TEXT,__text _main.R1.Match
00000000010a6600 l F __TEXT,__text _main.R10.Expected
00000000010a65e0 l F __TEXT,__text _main.R10.Match
00000000010a6640 l F __TEXT,__text _main.R11.Expected
00000000010a6620 l F __TEXT,__text _main.R11.Match
00000000010a6680 l F __TEXT,__text _main.R12.Expected
00000000010a6660 l F __TEXT,__text _main.R12.Match
00000000010a66c0 l F __TEXT,__text _main.R13.Expected
00000000010a66a0 l F __TEXT,__text _main.R13.Match
00000000010a6700 l F __TEXT,__text _main.R14.Expected
00000000010a66e0 l F __TEXT,__text _main.R14.Match
00000000010a6740 l F __TEXT,__text _main.R15.Expected
00000000010a6720 l F __TEXT,__text _main.R15.Match
00000000010a6780 l F __TEXT,__text _main.R16.Expected
00000000010a6760 l F __TEXT,__text _main.R16.Match
00000000010a67c0 l F __TEXT,__text _main.R17.Expected
00000000010a67a0 l F __TEXT,__text _main.R17.Match
00000000010a6800 l F __TEXT,__text _main.R18.Expected
00000000010a67e0 l F __TEXT,__text _main.R18.Match
00000000010a6840 l F __TEXT,__text _main.R19.Expected
00000000010a6820 l F __TEXT,__text _main.R19.Match
00000000010a6400 l F __TEXT,__text _main.R2.Expected
00000000010a63e0 l F __TEXT,__text _main.R2.Match
00000000010a6880 l F __TEXT,__text _main.R20.Expected
00000000010a6860 l F __TEXT,__text _main.R20.Match
00000000010a68c0 l F __TEXT,__text _main.R21.Expected
00000000010a68a0 l F __TEXT,__text _main.R21.Match
00000000010a6900 l F __TEXT,__text _main.R22.Expected
00000000010a68e0 l F __TEXT,__text _main.R22.Match
00000000010a6940 l F __TEXT,__text _main.R23.Expected
00000000010a6920 l F __TEXT,__text _main.R23.Match
00000000010a6980 l F __TEXT,__text _main.R24.Expected
00000000010a6960 l F __TEXT,__text _main.R24.Match
00000000010a69c0 l F __TEXT,__text _main.R25.Expected
00000000010a69a0 l F __TEXT,__text _main.R25.Match
00000000010a6a00 l F __TEXT,__text _main.R26.Expected
00000000010a69e0 l F __TEXT,__text _main.R26.Match
00000000010a6a40 l F __TEXT,__text _main.R27.Expected
00000000010a6a20 l F __TEXT,__text _main.R27.Match
00000000010a6440 l F __TEXT,__text _main.R3.Expected
00000000010a6420 l F __TEXT,__text _main.R3.Match
00000000010a6480 l F __TEXT,__text _main.R4.Expected
00000000010a6460 l F __TEXT,__text _main.R4.Match
00000000010a64c0 l F __TEXT,__text _main.R5.Expected
00000000010a64a0 l F __TEXT,__text _main.R5.Match
00000000010a6500 l F __TEXT,__text _main.R6.Expected
00000000010a64e0 l F __TEXT,__text _main.R6.Match
00000000010a6540 l F __TEXT,__text _main.R7.Expected
00000000010a6520 l F __TEXT,__text _main.R7.Match
00000000010a6580 l F __TEXT,__text _main.R8.Expected
00000000010a6560 l F __TEXT,__text _main.R8.Match
00000000010a65c0 l F __TEXT,__text _main.R9.Expected
00000000010a65a0 l F __TEXT,__text _main.R9.Match
00000000010a6a60 l F __TEXT,__text _main.mainThis reveals a very regular structure:
_main.main_main.R0.Match,_main.R0.Expected- …
_main.R27.Match,_main.R27.Expected
This pattern strongly suggests:
- There are 28 independent rules (
R0....R27).
Each rule provides:
Match(byte) bool— checks 1 characterExpected() byte— returns the character printed in the final message
3) Confirm program structure in _main.main
Disassembling _main.main shows three key behaviors:
- Read a line, then trim whitespace.
- Enforce length == 0x1c (28).
- For each position
iin0..27, callR{i}.Match(input[i]). - If all pass, build the output by concatenating
R{i}.Expected()for all i, then print it.
I spot the length constant in the disassembly:
llvm-objdump --disassemble --no-show-raw-insn --disassemble-symbols=_main.main memory_minder | grep '\$0x1c' 10a6f05: cmpq $0x1c, %rbx
10a6fd5: cmpq $0x1c, %rcx
10a7068: movl $0x1c, %esi
10a70a0: cmpq $0x1c, %rax4) Why each rule is “one compare”
Each Match function is effectively a single-byte compare against an immediate constant. For example:
llvm-objdump --disassemble --no-show-raw-insn --disassemble-symbols=_main.R0.Match memory_mindermemory_minder: file format mach-o 64-bit x86-64
Disassembly of section __TEXT,__text:
00000000010a6360 <_main.R0.Match>:
10a6360: cmpb $0x33, %al
10a6362: sete %al
10a6365: retq
10a6366: int3
10a6367: int3
10a6368: int3
10a6369: int3
10a636a: int3
10a636b: int3
10a636c: int3
10a636d: int3
10a636e: int3
10a636f: int3
10a6370: int3
10a6371: int3
10a6372: int3
10a6373: int3
10a6374: int3
10a6375: int3
10a6376: int3
10a6377: int3
10a6378: int3
10a6379: int3
10a637a: int3
10a637b: int3
10a637c: int3
10a637d: int3
10a637e: int3
10a637f: int3You will see the core instruction:
cmpb $0x33, %al— → input[0] must be0x33('3')
Each Expected returns 1 constant byte:
llvm-objdump --disassemble --no-show-raw-insn --disassemble-symbols=_main.R0.Expected memory_mindermemory_minder: file format mach-o 64-bit x86-64
Disassembly of section __TEXT,__text:
00000000010a6380 <_main.R0.Expected>:
10a6380: movl $0x48, %eax
10a6385: retq
10a6386: int3
10a6387: int3
10a6388: int3
10a6389: int3
10a638a: int3
10a638b: int3
10a638c: int3
10a638d: int3
10a638e: int3
10a638f: int3
10a6390: int3
10a6391: int3
10a6392: int3
10a6393: int3
10a6394: int3
10a6395: int3
10a6396: int3
10a6397: int3
10a6398: int3
10a6399: int3
10a639a: int3
10a639b: int3
10a639c: int3
10a639d: int3
10a639e: int3
10a639f: int3Core instruction:
movl $0x48, %eax→ output[0] is0x48('H')
So the solution is purely table extraction:
- “Scrambled memory” input = all
cmpbimmediates fromR0..R27.Match - “Truth” output = all
movlimmediates fromR0..R27.Expected
5) Extracted results
Required scrambled input (28 bytes)
_main.R0.Match : cmpb $0x33, %al -> 0x33 -> '3'
_main.R1.Match : cmpb $0x42, %al -> 0x42 -> 'B'
_main.R2.Match : cmpb $0x30, %al -> 0x30 -> '0'
_main.R3.Match : cmpb $0x4c, %al -> 0x4c -> 'L'
_main.R4.Match : cmpb $0x47, %al -> 0x47 -> 'G'
_main.R5.Match : cmpb $0x30, %al -> 0x30 -> '0'
_main.R6.Match : cmpb $0x57, %al -> 0x57 -> 'W'
_main.R7.Match : cmpb $0x4e, %al -> 0x4e -> 'N'
_main.R8.Match : cmpb $0x53, %al -> 0x53 -> 'S'
_main.R9.Match : cmpb $0x5f, %al -> 0x5f -> '_'
_main.R10.Match: cmpb $0x44, %al -> 0x44 -> 'D'
_main.R11.Match: cmpb $0x4e, %al -> 0x4e -> 'N'
_main.R12.Match: cmpb $0x31, %al -> 0x31 -> '1'
_main.R13.Match: cmpb $0x57, %al -> 0x57 -> 'W'
_main.R14.Match: cmpb $0x33, %al -> 0x33 -> '3'
_main.R15.Match: cmpb $0x52, %al -> 0x52 -> 'R'
_main.R16.Match: cmpb $0x5f, %al -> 0x5f -> '_'
_main.R17.Match: cmpb $0x52, %al -> 0x52 -> 'R'
_main.R18.Match: cmpb $0x59, %al -> 0x59 -> 'Y'
_main.R19.Match: cmpb $0x4d, %al -> 0x4d -> 'M'
_main.R20.Match: cmpb $0x30, %al -> 0x30 -> '0'
_main.R21.Match: cmpb $0x45, %al -> 0x45 -> 'E'
_main.R22.Match: cmpb $0x33, %al -> 0x33 -> '3'
_main.R23.Match: cmpb $0x4d, %al -> 0x4d -> 'M'
_main.R24.Match: cmpb $0x7b, %al -> 0x7b -> '{'
_main.R25.Match: cmpb $0x42, %al -> 0x42 -> 'B'
_main.R26.Match: cmpb $0x54, %al -> 0x54 -> 'T'
_main.R27.Match: cmpb $0x48, %al -> 0x48 -> 'H'3B0LG0WNS_DN1W3R_RYM0E3M{BTHProgram’s “truth” output (28 bytes), aka the flag.
HTB{M3M0RY_R3W1D_SNOWGL0B3}[Crypto] — “Disguised”
server.py contents (provided source code):
import json, hashlib, os
from utils import _msc, _ek, b2m, m2b, B
from Crypto.Util.Padding import pad
class HearthProtocol:
def __init__(self, cipher):
self.cipher = cipher
self.admin_uid = 0
self.uid = 1
def login(self, uid, username, token):
snowprint = hashlib.shake_256(self.cipher.KEY + username + str(uid).encode()).digest(64)
real_token = self.cipher.encrypt(json.dumps({"s": snowprint.hex(), "i": uid}).encode())
if real_token == token:
if uid == self.admin_uid and username == b'TinselwickAdmin':
return { "success": f"Warm greetings, admin! Your Starshard scroll: {open('flag.txt').read()}" }
else:
return { "success": f"Welcome {username.decode()}! No Starshard scrolls for you today." }
else:
return { "error": "Frostbitten session token. Identity unclear." }
def register(self, username):
if self.uid >= 32:
return { "error": "The Hearth Registry is full for now... try again after the solstice." }
snowprint = hashlib.shake_256(self.cipher.KEY + username + str(self.uid).encode()).digest(64)
token = self.cipher.encrypt(json.dumps({"s": snowprint.hex(), "i": self.uid}).encode())
self.uid += 1
return { "token": token.hex() }
class SnowCipher:
def __init__(self, key):
self.KEY = key
def _sb(self, s, b=B):
return [[b[val] for val in row] for row in s]
def _sr(self, s):
res = [s[i].copy() for i in range(4)]
res[0][1], res[1][1], res[2][1], res[3][1] = res[1][1], res[2][1], res[3][1], res[0][1]
res[0][2], res[1][2], res[2][2], res[3][2] = res[2][2], res[3][2], res[0][2], res[1][2]
res[0][3], res[1][3], res[2][3], res[3][3] = res[3][3], res[0][3], res[1][3], res[2][3]
return res
def _mc(self, s):
return [_msc(s[i].copy()) for i in range(4)]
def _ark(self, s, k):
return [[t[0] ^ t[1] for t in list(zip(row[0], row[1]))] for row in zip(s, k)]
def encrypt_block(self, block):
rk = _ek(self.KEY)
s = b2m(block)
s = self._ark(s, rk[0])
s = self._sb(s)
s = self._sr(s)
s = self._mc(s)
s = self._ark(s, rk[1])
return m2b(s)
def encrypt(self, m):
plaintext = pad(m, 16)
return b''.join(self.encrypt_block(plaintext[i:i+16]) for i in range(0, len(plaintext), 16))
prot = HearthProtocol(SnowCipher(os.urandom(32)))
while True:
print("[1] Request Hearth Token")
print("[2] Authenticate with Hearth Token")
print("[3] Leave Frostgate")
choice = input("> ").strip()
if choice == "1":
username = input("Enter username: ").strip().encode()
response = prot.register(username)
elif choice == "2":
try:
uid = int(input("Enter UID: ").strip())
except ValueError:
print('[-] UID must be numeric.')
continue
username = input("Enter username: ").strip().encode()
token_hex = input("Enter token (hex): ").strip()
token = bytes.fromhex(token_hex)
response = prot.login(uid, username, token)
elif choice == "3":
print("The Frostgate closes... stay warm.")
break
else:
print("Try a valid option, snowflake.")
continue
print(json.dumps(response))Challenge summary
The service exposes two actions:
- Request Hearth Token: returns a hex “token” for a username.
- Authenticate: checks whether a provided
(uid, username, token)matches what the server would generate.
Admin access is granted only if uid == 0 and username == b"TinselwickAdmin"
The “token” is not a signature/MAC. It is encrypt(json.dumps({"s": snowprint_hex, "i": uid})).
Code audit highlights
Deterministic “snowprint”
For both register and login, the server derives:
snowprint = SHAKE256(KEY || username || str(uid)).digest(64)
Then it JSON-serializes {"s": snowprint.hex(), "i": uid} and encrypts it to produce the token.
The cipher is “1-round AES-like” in ECB
The encryption is block-based with PKCS#7 padding and no IV; each block is encrypted independently (ECB).
Each block uses only one SubBytes/ShiftRows/MixColumns layer between two AddRoundKey steps:
s = ARK(s, rk[0])
s = SB(s)
s = SR(s)
s = MC(s)
s = ARK(s, rk[1])Also, the key is freshly random per server process: os.urandom(32).
Exploit strategy
Because the server gives you an encryption oracle over a highly structured plaintext (JSON with fixed fields), and the cipher is only one round, you can recover the round keys using “reduced-round AES” style key recovery:
- The mapping up to the final round key is:
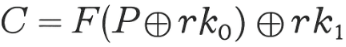
where F = MC ∘ SR ∘ SB
- XOR cancels the final round key:
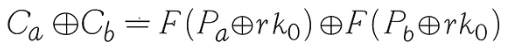
- Because SR and MC are linear, it can be inverted on the XOR difference, reducing the problem to per-byte constraints through the S-box:
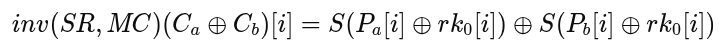
This yields independent constraints for each key byte rk0[i] solvable by brute-forcing 0 to 255.
How we get known plaintext bytes
Even though snowprint.hex() is unknown, JSON gives enough known structure:
- The 1st block begins with a constant prefix like
{"s": "(known bytes). - Another block contains the constant substring
", "i":(known bytes). - The final block contains the trailing
}plus PKCS#7 padding; importantly, padding is known.
The UID is also embedded in the JSON as a digit string; by collecting a token at UID 1 and another at UID 10, the last-block plaintext changes in a predictable way (1 digit vs 2 digits), which is enough to disambiguate key-byte candidates. The fact that UID increments on each registration makes it easy to obtain those 2 samples.
Operationally:
- Call Request token repeatedly until theres tokens for UID=1 and UID=10 (10 requests total in one connection).
- Use ciphertext blocks from those tokens to recover
rk0byte-by-byte (256 candidates each; pruned to 1 with two constraints). - Once
rk0is known, computerk1from any known plaintext block:

Forging the admin token
With the recovered key material:
Compute the admin snowprint exactly as the server does:
SHAKE256(KEY || b"TinselwickAdmin" || b"0").digest(64).hex()
Build the JSON:
{“s”: <snowprint_hex>, “i”: 0}
Encrypt it with the same cipher and padding rules.
Authenticate with:
- UID
0 - username
TinselwickAdmin - the forged token hex
In my case:
cbc96cf168a9143a87ecfa37485f81bb479ff5252f1f5f2acf02ebe5352c6e7e25ad5dae69d4e9f16e22d15de78591d2661084cb4574278372d97ded80d5fa6d0a4cc7a15e5b43ee76bf4af15b98e5d4f1089fc0f84042d947219c3ca3f0c211ee3a3d3da6de35a97f932d4719400ce5a00d7536fbb92d459ece0deb10ffc5ac84a78a3f92b99057fcdccd41272d9521147f2bf21a6c0dbb1cdb173788095e9bOn success, the server returns the flag.

Solver code:
#!/usr/bin/env python3
import sys, json, hashlib
# AES S-box
SBOX = [
0x63,0x7c,0x77,0x7b,0xf2,0x6b,0x6f,0xc5,0x30,0x01,0x67,0x2b,0xfe,0xd7,0xab,0x76,
0xca,0x82,0xc9,0x7d,0xfa,0x59,0x47,0xf0,0xad,0xd4,0xa2,0xaf,0x9c,0xa4,0x72,0xc0,
0xb7,0xfd,0x93,0x26,0x36,0x3f,0xf7,0xcc,0x34,0xa5,0xe5,0xf1,0x71,0xd8,0x31,0x15,
0x04,0xc7,0x23,0xc3,0x18,0x96,0x05,0x9a,0x07,0x12,0x80,0xe2,0xeb,0x27,0xb2,0x75,
0x09,0x83,0x2c,0x1a,0x1b,0x6e,0x5a,0xa0,0x52,0x3b,0xd6,0xb3,0x29,0xe3,0x2f,0x84,
0x53,0xd1,0x00,0xed,0x20,0xfc,0xb1,0x5b,0x6a,0xcb,0xbe,0x39,0x4a,0x4c,0x58,0xcf,
0xd0,0xef,0xaa,0xfb,0x43,0x4d,0x33,0x85,0x45,0xf9,0x02,0x7f,0x50,0x3c,0x9f,0xa8,
0x51,0xa3,0x40,0x8f,0x92,0x9d,0x38,0xf5,0xbc,0xb6,0xda,0x21,0x10,0xff,0xf3,0xd2,
0xcd,0x0c,0x13,0xec,0x5f,0x97,0x44,0x17,0xc4,0xa7,0x7e,0x3d,0x64,0x5d,0x19,0x73,
0x60,0x81,0x4f,0xdc,0x22,0x2a,0x90,0x88,0x46,0xee,0xb8,0x14,0xde,0x5e,0x0b,0xdb,
0xe0,0x32,0x3a,0x0a,0x49,0x06,0x24,0x5c,0xc2,0xd3,0xac,0x62,0x91,0x95,0xe4,0x79,
0xe7,0xc8,0x37,0x6d,0x8d,0xd5,0x4e,0xa9,0x6c,0x56,0xf4,0xea,0x65,0x7a,0xae,0x08,
0xba,0x78,0x25,0x2e,0x1c,0xa6,0xb4,0xc6,0xe8,0xdd,0x74,0x1f,0x4b,0xbd,0x8b,0x8a,
0x70,0x3e,0xb5,0x66,0x48,0x03,0xf6,0x0e,0x61,0x35,0x57,0xb9,0x86,0xc1,0x1d,0x9e,
0xe1,0xf8,0x98,0x11,0x69,0xd9,0x8e,0x94,0x9b,0x1e,0x87,0xe9,0xce,0x55,0x28,0xdf,
0x8c,0xa1,0x89,0x0d,0xbf,0xe6,0x42,0x68,0x41,0x99,0x2d,0x0f,0xb0,0x54,0xbb,0x16
]
def pkcs7_pad(m: bytes, bs: int = 16) -> bytes:
padlen = bs - (len(m) % bs)
return m + bytes([padlen]) * padlen
def xor_bytes(a: bytes, b: bytes) -> bytes:
return bytes(x ^ y for x, y in zip(a, b))
def b2m(block: bytes):
return [[block[4*c + r] for r in range(4)] for c in range(4)]
def m2b(m):
out = bytearray(16)
for c in range(4):
for r in range(4):
out[4*c + r] = m[c][r] & 0xff
return bytes(out)
def shift_rows(s):
res = [col.copy() for col in s]
res[0][1], res[1][1], res[2][1], res[3][1] = res[1][1], res[2][1], res[3][1], res[0][1]
res[0][2], res[1][2], res[2][2], res[3][2] = res[2][2], res[3][2], res[0][2], res[1][2]
res[0][3], res[1][3], res[2][3], res[3][3] = res[3][3], res[0][3], res[1][3], res[2][3]
return res
def inv_shift_rows(s):
res = [col.copy() for col in s]
res[0][1], res[1][1], res[2][1], res[3][1] = res[3][1], res[0][1], res[1][1], res[2][1]
res[0][2], res[1][2], res[2][2], res[3][2] = res[2][2], res[3][2], res[0][2], res[1][2]
res[0][3], res[1][3], res[2][3], res[3][3] = res[1][3], res[2][3], res[3][3], res[0][3]
return res
def sub_bytes(s):
return [[SBOX[v] for v in col] for col in s]
def xtime(a: int) -> int:
return ((a << 1) ^ 0x1b) & 0xff if (a & 0x80) else ((a << 1) & 0xff)
def gf_mul(a: int, b: int) -> int:
res = 0
aa, bb = a, b
while bb:
if bb & 1:
res ^= aa
aa = xtime(aa)
bb >>= 1
return res
def mix_single_column(col):
a0, a1, a2, a3 = col
return [
gf_mul(a0,2) ^ gf_mul(a1,3) ^ a2 ^ a3,
a0 ^ gf_mul(a1,2) ^ gf_mul(a2,3) ^ a3,
a0 ^ a1 ^ gf_mul(a2,2) ^ gf_mul(a3,3),
gf_mul(a0,3) ^ a1 ^ a2 ^ gf_mul(a3,2),
]
def inv_mix_single_column(col):
a0, a1, a2, a3 = col
return [
gf_mul(a0,14) ^ gf_mul(a1,11) ^ gf_mul(a2,13) ^ gf_mul(a3,9),
gf_mul(a0,9) ^ gf_mul(a1,14) ^ gf_mul(a2,11) ^ gf_mul(a3,13),
gf_mul(a0,13) ^ gf_mul(a1,9) ^ gf_mul(a2,14) ^ gf_mul(a3,11),
gf_mul(a0,11) ^ gf_mul(a1,13) ^ gf_mul(a2,9) ^ gf_mul(a3,14),
]
def mix_columns(s):
return [mix_single_column(col) for col in s]
def inv_mix_columns(s):
return [inv_mix_single_column(col) for col in s]
def ark(s, k):
return [[x ^ y for x, y in zip(col, kcol)] for col, kcol in zip(s, k)]
def blocks(ct: bytes):
return [ct[i:i+16] for i in range(0, len(ct), 16)]
def p9(uid: int) -> bytes:
if uid < 10:
return bytes([ord('}')]) + bytes([0x0f]) * 15
last_digit = str(uid).encode()[1]
return bytes([last_digit, ord('}')]) + bytes([0x0e]) * 14
def deltaY_from_cipher_pair(Ca: bytes, Cb: bytes) -> bytes:
dC = xor_bytes(Ca, Cb)
st = b2m(dC)
st = inv_mix_columns(st)
st = inv_shift_rows(st)
return m2b(st)
def recover_rk0(token1: bytes, token10: bytes) -> bytes:
b1 = blocks(token1)
b10 = blocks(token10)
C0_1, C8_1, C9_1 = b1[0], b1[8], b1[9]
C9_10 = b10[9]
pref = b'{"s": "'
suffix = b'", "i": '
digit1 = ord('1')
P9_1 = p9(1)
P9_10 = p9(10)
d0_91 = deltaY_from_cipher_pair(C0_1, C9_1)
d0_910 = deltaY_from_cipher_pair(C0_1, C9_10)
d8_91 = deltaY_from_cipher_pair(C8_1, C9_1)
d8_910 = deltaY_from_cipher_pair(C8_1, C9_10)
rk0 = bytearray(16)
for pos in range(0, 7):
a = pref[pos]
cand = [k for k in range(256)
if (SBOX[a ^ k] ^ SBOX[P9_1[pos] ^ k]) == d0_91[pos]
and (SBOX[a ^ k] ^ SBOX[P9_10[pos] ^ k]) == d0_910[pos]]
if len(cand) != 1:
raise RuntimeError(f"rk0 byte {pos} ambiguous (got {len(cand)})")
rk0[pos] = cand[0]
for i in range(8):
pos = 7 + i
a = suffix[i]
cand = [k for k in range(256)
if (SBOX[a ^ k] ^ SBOX[P9_1[pos] ^ k]) == d8_91[pos]
and (SBOX[a ^ k] ^ SBOX[P9_10[pos] ^ k]) == d8_910[pos]]
if len(cand) != 1:
raise RuntimeError(f"rk0 byte {pos} ambiguous (got {len(cand)})")
rk0[pos] = cand[0]
pos = 15
a = digit1
cand = [k for k in range(256)
if (SBOX[a ^ k] ^ SBOX[P9_1[pos] ^ k]) == d8_91[pos]
and (SBOX[a ^ k] ^ SBOX[P9_10[pos] ^ k]) == d8_910[pos]]
if len(cand) != 1:
raise RuntimeError(f"rk0 byte {pos} ambiguous (got {len(cand)})")
rk0[pos] = cand[0]
return bytes(rk0)
def compute_rk1(rk0_bytes: bytes, token1: bytes) -> bytes:
C9_1 = blocks(token1)[9]
P9_1 = p9(1)
s = b2m(P9_1)
s = ark(s, b2m(rk0_bytes))
s = sub_bytes(s)
s = shift_rows(s)
s = mix_columns(s)
W = m2b(s)
return xor_bytes(C9_1, W)
def encrypt_block(block: bytes, rk0_bytes: bytes, rk1_bytes: bytes) -> bytes:
s = b2m(block)
s = ark(s, b2m(rk0_bytes))
s = sub_bytes(s)
s = shift_rows(s)
s = mix_columns(s)
s = ark(s, b2m(rk1_bytes))
return m2b(s)
def encrypt(msg: bytes, rk0_bytes: bytes, rk1_bytes: bytes) -> bytes:
pt = pkcs7_pad(msg, 16)
out = bytearray()
for i in range(0, len(pt), 16):
out += encrypt_block(pt[i:i+16], rk0_bytes, rk1_bytes)
return bytes(out)
def main(argv):
if len(argv) < 2:
print("Usage: python3 solve.py <token_uid1_hex> <token_uid2_hex> ... <token_uidN_hex>")
sys.exit(1)
toks = [bytes.fromhex(x.strip()) for x in argv[1:]]
for i,t in enumerate(toks, start=1):
if len(t) != 160:
raise SystemExit(f"Token #{i} wrong length (expected 160 bytes).")
token1 = toks[0]
last_block_uid_lt10 = token1[-16:]
token10 = None
for t in toks[1:]:
if t[-16:] != last_block_uid_lt10:
token10 = t
break
if token10 is None:
raise SystemExit("I didn't see any UID>=10 token. Collect up through UID 10 in the SAME nc session.")
rk0 = recover_rk0(token1, token10)
rk1 = compute_rk1(rk0, token1)
KEY = rk0 + rk1 # works because the first two round keys are the 32-byte key in this construction
uid = 0
username = b"TinselwickAdmin"
snow_hex = hashlib.shake_256(KEY + username + str(uid).encode()).digest(64).hex()
msg = json.dumps({"s": snow_hex, "i": uid}).encode()
admin_token = encrypt(msg, rk0, rk1).hex()
print(admin_token)
if __name__ == "__main__":
main(sys.argv)[Coding] — “Cellcode”
“Felix Brambletail — Tinselwick’s Hot Cocoa Coder — doesn’t just stir marshmallows. Between Everlight rehearsals, he runs tiny “life spells” on enchanted petri dishes, where living sugar-cells blink like little lanterns.
This year, Felix and Tilda Baublenose noticed something eerie: the dish’s living patterns were syncing with the Starshard Bauble’s flicker logs. And at the exact moment the Bauble vanished, both records seemed to rewind — as if a corrupted line of festive magic had been rejected and rolled back.
Felix needs a simulator he can trust: a precise way to evolve the dish forward in time, one generation at a time, following a spell-rule that controls when dead cells awaken and when living cells endure.
Your task is to simulate the dish for T generations. Each generation updates all cells in parallel based on the number of alive neighbors (up to 8 surrounding cells inside the grid), using the provided rulestring.
Input format:
- The first line is an integer N, the size of the grid (N x N) representing Felix’s petri dish.
- The next N lines each contain N characters (0 or 1) representing the initial state of the dish.
— 0 = dead cell, 1 = alive cell
- The next line is a rulestring for birth and survival in the format “Bx/Sy” where x and y are sequences of digits (e.g: B3/S23).
— B = birth conditions (dead cell becomes alive)
— B3 means a dead cell with exactly 3 alive neighbors becomes alive
— S = survival conditions (alive cell stays alive)
— S23 means an alive cell with 2 or 3 alive neighbors stays alive
- The last line contains an integer T, the number of generations to simulate (how many “ticks” Felix and Tilda let the experiment run).
Output format:
- Print the final grid after T generations.
- The output should be N lines each containing N characters (0 or 1) representing the final state of the grid.
- The output grid should maintain the same format as the input grid.
2 <= N <= 750
0 <= Birth/Survival condition <= 6
1 <= T <= 6
Example:
Input:
5
0111
0101
1101
0100
B25/S05
2
Expected output:
1000
0100
0010
0000
The initial grid is a 4x4 matrix with a mix of alive (1) and dead (0) cells on Felix’s enchanted petri dish.
The rulestring “B25/S05” indicates that:
- A dead cell becomes alive if it has exactly 2 or 5 alive neighbors (B25).
- An alive cell survives only if it has 0 or 5 alive neighbors (S05).
- All the 8 surrounding cells are considered neighbors (up, down, left, right, and diagonals), as long as they are inside the grid.
After 1st generation:
1000
0000
0010
0000
After 2nd generation:
1000
0100
0010
0000”
Context and goal
“Cellcode” is a small cellular automaton simulator. The input is an N x N grid of dead/alive cells (0/1), a rulestring in the common Life-like format Bx/Sy, and a small number of generations T to simulate. Each tick updates the entire grid in parallel using the count of alive neighbors in the 8 surrounding positions, considering only neighbors that remain inside the grid (no wraparound). The output is the final grid after T generations in the same 0/1 text form.
Input & Rule Interpretation
The rulestring splits into two parts: birth conditions B... and survival conditions S.... A dead cell becomes alive if its live-neighbor count is listed in B, and an alive cell remains alive if its count is listed in S; otherwise it becomes dead. Although the prompt mentions neighbor counts up to 6, the neighborhood is explicitly 8-directional, so the implementation treats valid counts as 0..8 and simply ignores anything not in that range.
Idea
Each generation requires computing neighbor counts for every cell and applying the birth/survival lookup. With N up to 750 and T up to 6, a direct O(T * N^2) solution is appropriate. In Python, the solution uses a padded border of 0s around the grid. That eliminates per-cell bounds checks: every interior cell can sum its eight neighbors by indexing the three rows around it at positions j-1, j, j+1. Birth/survival conditions are stored as small lookup arrays (birth[count], survive[count]) so rule application is a constant-time table hit.
Solver Code:
import sys
def main() -> None:
lines = sys.stdin.buffer.read().splitlines()
if not lines:
return
idx = 0
n = int(lines[idx].strip())
idx += 1
zero = bytearray(n + 2) # padding border (all zeros)
grid = [zero]
for _ in range(n):
line = lines[idx].strip()
idx += 1
row = bytearray(n + 2)
# Convert ASCII '0'/'1' -> 0/1
row[1:n + 1] = bytearray(b - 48 for b in line)
grid.append(row)
grid.append(zero)
rule = lines[idx].strip().decode()
idx += 1
t = int(lines[idx].strip()) if idx < len(lines) else 0
# Parse rulestring: "Bx/Sy"
birth = [0] * 9
surv = [0] * 9
if "/" in rule:
b_part, s_part = rule.split("/", 1)
else:
b_part, s_part = rule, ""
b_digits = b_part[1:] if b_part.startswith("B") else b_part
s_digits = s_part[1:] if s_part.startswith("S") else s_part
for ch in b_digits:
if "0" <= ch <= "8":
birth[ord(ch) - 48] = 1
for ch in s_digits:
if "0" <= ch <= "8":
surv[ord(ch) - 48] = 1
# Simulate T generations
for _ in range(t):
new_grid = [zero]
btab = birth
stab = surv
for i in range(1, n + 1):
r0 = grid[i - 1]
r1 = grid[i]
r2 = grid[i + 1]
new_row = bytearray(n + 2)
for j in range(1, n + 1):
cnt = (
r0[j - 1] + r0[j] + r0[j + 1]
+ r1[j - 1] + r1[j + 1]
+ r2[j - 1] + r2[j] + r2[j + 1]
)
new_row[j] = stab[cnt] if r1[j] else btab[cnt]
new_grid.append(new_row)
new_grid.append(zero)
grid = new_grid
# Output without padding
table = bytes.maketrans(b"\x00\x01", b"01")
out_lines = [
bytes(grid[i][1:n + 1]).translate(table)
for i in range(1, n + 1)
]
sys.stdout.buffer.write(b"\n".join(out_lines))
if __name__ == "__main__":
main()
Result

[Coding] — “Bauble Sort”
“In the quiet hours before Everlight Eve, Tilda Baublenose uncovered a fragment of the ancient Bauble Registry — an enchanted log used to catalog every magical ornament in Tinselwick.
Each bauble is recorded with:
• its unique identifier,
• its sparkle power,
• and its glow stability.
But after the Starshard Bauble vanished, the registry was left in disarray — scrambled by corrupted festive magic.
To restore the registry, the baubles must be sorted using the following enchanted rules:
1. Baubles with higher sparkle power must come first.
2. If two baubles have the same sparkle power, the one with lower stability comes first.
3. If both sparkle and stability are the same, the baubles are ordered alphabetically by their identifier.
As Tilda, you must restore the correct order of the registry so the festival systems can safely reboot. Only once the baubles are properly sorted can the magic of Everlight begin to flow again.
The input has the following format:
The first line contains a single integer N, the number of baubles.
The next N lines each contain:
A bauble identifier (string without spaces),
An integer sparkle value,
An integer stability value.
Each line follows the format: “identifier: sparkle , stability”
Print the identifiers of the baubles in the correct sorted order, one per line.
10 ≤ N ≤ 500000
0 ≤ sparkle ≤ 1000
0 ≤ stability ≤ 1000
Example:
Input:
3
starwishbell_01f106: 10 , 3
tinselflaredrop_7a0b68: 10 , 1
glimmerglowheart_a00165: 7 , 0
Expected output:
tinselflaredrop_7a0b68
starwishbell_01f106
glimmerglowheart_a00165"
Context & Goal
The challenge provides a “registry” of baubles, each with an identifier plus two integers: sparkle and stability. The task is to output the identifiers sorted by these rules: higher sparkle first, then lower stability, then identifier in alphabetical order if both numbers match.
Input format
First line: N
Next N lines: identifier: sparkle , stability (note the colon and comma, plus variable whitespace)
Idea
Parse each line into (identifier, sparkle, stability), then sort using a tuple key that matches the priority rules. In Python, descending sparkle is handled by negating it in the key: (-sparkle, stability, identifier).
Solver Code:
import sys
data = sys.stdin.buffer.read().decode().splitlines()
if not data:
raise SystemExit
n = int(data[0].strip())
items = []
for i in range(1, n + 1):
line = data[i].strip()
# Format: "identifier: sparkle , stability"
ident, rest = line.split(':', 1)
rest = rest.strip()
sparkle_str, stability_str = rest.split(',', 1)
sparkle = int(sparkle_str.strip())
stability = int(stability_str.strip())
# Sort key: sparkle desc, stability asc, identifier asc
items.append((-sparkle, stability, ident))
items.sort()
sys.stdout.write("\n".join(ident for _, __, ident in items))Result

[Coding] — “Flickering Snowglobe”
High above Tinselwick, the Great Snowglobe atop Sprucetop Tower is supposed to glow in smooth, gentle patterns — a steady orchestra of magical pulses that keeps the Festival of Everlight in harmony.
Each moment, the Snowglobe emits a tiny pulse:
• ‘.’ for a short flicker
• ‘-’ for a long shimmer
• ‘*’ for a bright spark
Normally these pulses form long, stable bands of the same type. But since the Starshard Bauble fled, the glow has begun to stutter — breaking into many short, uneven chunks.
Tilda Baublenose has captured a log of the Snowglobe’s pulses as a single string. She wants to know how many stable segments the Snowglobe’s glow has fractured into.
A stable segment is defined as a maximal contiguous sequence of the same pulse character.
For example, the sequence “.. — ***.-” is broken into the segments:
* “..”
* “ — “
* “***”
* “.”
* “-”
a total of 5 stable segments.
Your task is to analyze the Snowglobe’s flicker log and determine how many stable segments it contains.
The input has the following format:
The first line contains a single integer N, the length of the pulse string S.
The second line contains the pulse string S, which consists of the characters ‘.’, ‘-’, and ‘*’.
Print a single integer — the number of stable segments in the pulse string.
1 ≤ N ≤ 1⁰⁶
Example:
Input:
… — ***.-
Expected output:
5
We are given the pulse string:
… — ***.-
We break it into maximal contiguous segments of identical characters:
1. … (three short flickers .)
2. — (two long shimmers -)
3. *** (three bright sparks *)
4. . (a single short flicker .)
5. — (a single long shimmer -)
There are 5 such stable segments in total, so the correct output is 5.”
Context and goal
The challenge provides a “pulse log” string S over the characters ., -, and *. A stable segment is defined as a maximal contiguous sequence of the same character (a run). The goal is to compute how many such runs appear in S.
Instruction and context from the prompt
The input format is:
- First line: an integer
N, the length ofS - Second line: the string
Sconsisting only of.,-, and*
The program must output a single integer: the # of stable segments in S.
The only rule that matters is the run definition: a segment is maximal, contiguous, and consists of identical pulse characters. Equivalently, a new segment begins exactly when the current character differs from the previous one.
Idea
Instead of explicitly splitting the string, count boundaries. For any non-empty S, the number of runs is 1 + the number of indices i where S[i] != S[i-1]. This is a single left-to-right pass, which is optimal for N up to 10^6.
Solver code:
import sys
data = sys.stdin.read().split()
if not data:
raise SystemExit(0)
# Expected format: N then S, but tolerate inputs that only provide S.
if len(data) == 1:
s = data[0]
else:
s = data[1] if data[0].isdigit() else data[0]
segments = 1
for i in range(1, len(s)):
if s[i] != s[i - 1]:
segments += 1
print(segments)